Исследователи Массачусетского технологического института утверждают, что им удалось выявить в большой языковой Llama 2 модель пространства и времени. Их работа говорит, что нейросеть имеет понимание положения географических мест на планете и исторических событий.
Большие языковые модели (БЯМ) кодируют слова в токены, а затем анализируют связи между ними на основе текстовых данных. На основе выявленных закономерностей модель может продолжать любой текст, предсказывая следующий токен.
При всей внешней примитивности объяснения принципов работы БЯМ они продемонстрировали неоспоримые способности. Исследователей интересует, что на самом деле таит в себе модель и что она знает.
Некоторые гипотезы утверждают, что в БЯМ остался набор корреляций, а не связная модель или «понимание» мира. Так говорят, например, доклады «Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data» (DOI:O10.18653/v1/2020.acl-main.463) и «Experience Grounds Language» (arXiv:2004.10151). Первый приводит, в числе прочего, разнообразные мысленные эксперименты и анализирует само понятие интеллекта; второй приходит к выводу, что для глубокого понимания вопросов языка нужен физический и социальный контекст.
В других случаях говорят, что БЯМ просто сжимают информацию, а затем составляют более компактную, связную и интерпретируемую модель генеративных процессов, лежащих в основе данных обучения. К примеру, в 2022 году было показано (arXiv:2210.13382), что модель на трансформерах для предсказания следующего хода в игре реверси выучила представления состояния игры. В дальнейшем научная работа 2023 года демонстрирует (arXiv:2309.00941), что эти представления линейны.
Другие доклады показывали, что БЯМ отслеживают состояния субъектов в контексте (arXiv:2106.00737), понимают концептуальные структуры нелингвистического мира — цвета́ и направления (доклад Mapping Language Models to Grounded Conceptual Spaces; arXiv:2109.06129v2). Вообще, подобные вопросы часто (DOI:10.1145/3442188.3445922; DOI:10.1145/3531146.3533088; arXiv:2108.07258; arXiv:2306.12001; arXiv:2209.00626) интересуют исследователей в контексте безопасности, избегания или хотя бы уменьшения социоэкономических рисков.
Научная работа аспиранта Уэса Гарни и профессора Макса Тегмарка не пытается усыпить читателя полуфилософскими рассуждениями и гипотетическими катастрофическими рисками. Эти исследователи Массачусетского технологического института нарисовали карту мира и даже выделили отдельные регионы Соединённых Штатов Америки в том виде, как их видит БЯМ. Как следует из названия «Language Models Represent Space and Time», в том числе была проведена оценка представления времени.
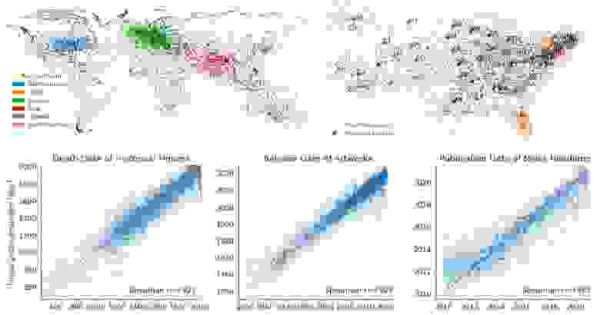
Модель мира в представлении Llama 2 с 70 млрд параметров при увеличении числа слоёв. Цветом закодированы реальные материки. Уэс Гарни
Гарни даже красочно пересказал содержание в виде треда в личном микроблоге. Анализировалась БЯМ Llama 2 запрещённых в России экстремистов из Meta. Для экспериментов брались три варианта модели: с 70, 13 и 7 миллиардами параметров.
Для исследования подготовили имена десятков тысяч городов, структур и природных объектов. Это могли быть как естественные элементы рельефа (включая озёра и острова) и субъекты государственного подчинения (графства, округа, города), так и просто известные здания (к примеру, отель или университет) или элементы инфраструктуры (парки, мосты). Датасетов было три: весь мир, США и Нью-Йорк. Данные собрали из DBpedia, отчётов переписи США и NYC OpenData.
БЯМ получала на входе каждое из названий, возможно, с небольшим промптом. При этом для каждого слоя сохранялись активации скрытого состояния и последнего токена.
Новых методов пробинга изобретать не стали, взяли уже известные (arXiv:2304.03659; DOI:10.1162/coli_a_00422). В рамках пробинга выявлялось соответствие элементов активационного датасета с целью — глобальными координатами.
В итоге получается красивая анимация, где при переходе от слоя к слою уточняется местоположение точек на карте.
Модель США в представлении Llama 2 с 70 млрд параметров при увеличении числа слоёв. Цветом закодированы штаты материковой части США. Уэс Гарни
Чтобы показать, насколько хорошо БЯМ ориентируется во времени, собрали датасеты с известными историческими личностями, объектами культуры и заголовками газеты «Нью-Йорк таймс». Датасет людей содержал исторические личности, жившие в последние 3 тыс. лет, датасет культурных объектов — песни, фильмы и книги с пятидесятых годов прошлого века, заголовков — с 2010 года. Соответственно, оценка из БЯМ показывает дату смерти, публикации или выхода статьи.
Здесь пробинг соотносил с изначальным датасетом не координаты, а год.

Для каждой точки положение на горизонтальной оси указывает реальную дату события, вертикальной — оценку. Чем дальше отходит точка от красной линии, тем хуже результат. Использована модель Llama 2 с 70 млрд параметров
Уэс Гарни поясняет анализ результатов. Было выявлено, что уже на ранних слоях постепенно возникает представление, которое быстро выходит на плато уже к середине.
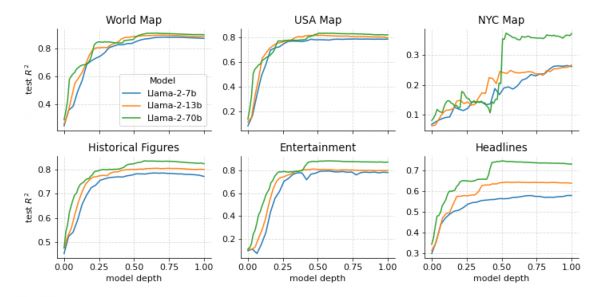
Оценка производительности вне выборки [out-of-sample performance] на основе значения R²
Как и ожидалось, модели с бо́льшим числом параметров работают лучше. При этом для более узких областей точность ниже — речь про то, что в географии Нью-Йорка Llama 2 разбирается хуже.
Может ли контекст промпта к БЯМ поменять результат? Как оказалось, не сильно.
Чтобы это выяснить, промпты варьировались множеством способов. Часть из них были пустыми, часть — содержали релевантный уточняющий вопрос. В последнем случае речь идёт про, например, просьбу назвать долготу и широту или год издания, для датасетов США и Нью-Йорка — где в, соответственно, США или в Нью-Йорке находится это место. Проводились также тесты, когда имена сущностей из датасетов приводились к заглавным буквам. Для датасета заголовков пробинг проводили в вариантах с точкой или без. Иногда в промпт просто добавляли случайные токены.
Обнаружилось, что нет заметного эффекта от уточняющей части вопроса «где находится в США»/«где находится в Нью-Йорке». Запись заглавными также слабо что-либо меняет, пусть и может мешать представлению текстовой сущности в виде токенов. А вот добавление случайных отвлекающих токенов значительно снижало производительность. Добавление точки к заголовку напротив, улучшало результат.
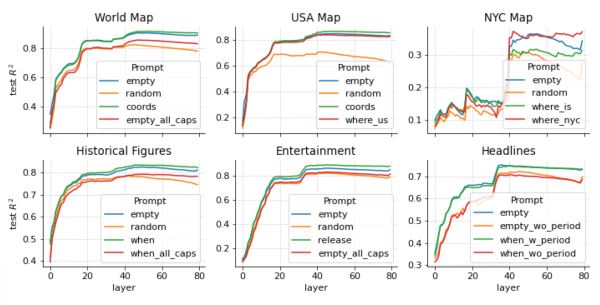
Оценка производительности вне выборки [out-of-sample performance] на основе значения R² с различными модификациями промпта
Модель действительно использует эти представления, говорит анализ нейронов с похожими весами на те, что использовались в пробинге. Были выявлены нейроны, которые чувствительны к координатам в пространстве или временно́му периоду сущности, что показывает наличие понимания глобальной геометрии.
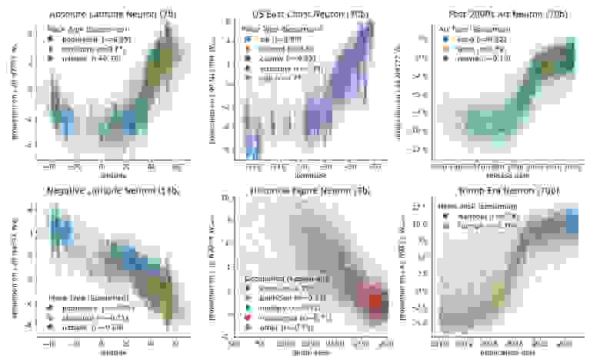
Нейроны места и времени в моделях Llama 2 с различным числом параметров. Здесь изображён результат проекции активационных датасетов на веса нейронов, для разных типов сущностей сравниваются координаты места или времени с корреляцией Спирмена
При всей заявленной оригинальности научной работы исследователи не упоминают, что подобный эффект уже известен более пяти лет. К примеру, в лекции Джереми Говарда от 2018 года на 29-й минуте идёт обсуждение научной работы 2016 года со схожим результатом.
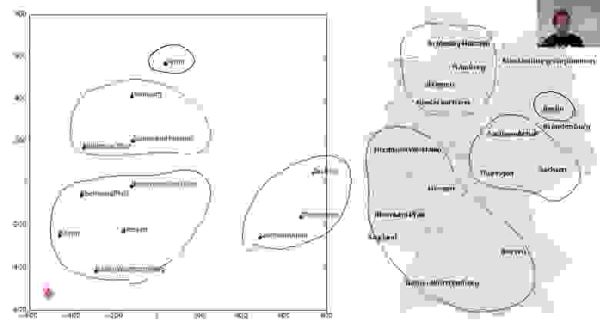
Наконец, похожее существует в алгоритмах word2vec, впервые опубликованных в 2013 году. Уже десять лет назад выражение Moscow − Russia + Japan приводило к ответу tokyo, что также можно представить как понимание географии.
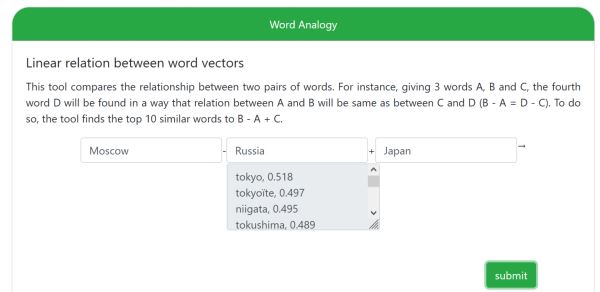
Онлайн-версия world2vec
Работу из МТИ раскритиковал глава отдела генеративных моделей и команды инференса в DeepMind Данило Дж. Резенде. В двух твитах он указал, что модель лишь изучает независимые факторы в варьировании данных (местоположение, время) и что похожим образом это происходит в автокодировщиках. Чтобы доказать, что это действительно модель мира, нужно продемонстрировать стабильные к внешним воздействиям механизмы. БЯМ должна изучить правила и отношения, которые независимы от конкретных случаев в скормленных ей датасетах, говорит Резенде. Впрочем, он считает, что это хороший шаг в улучшении понимания БЯМ.
Исследователи выложили всю экспериментальную инфраструктуру проекта, включая очищенные файлы CSV с именами сущностей и метаданными, в репозитории github.com/wesg52/world-models. Обещается, что в ближайшие недели будет опубликована минимальная версия кода для запуска базовых экспериментов на датасетах.
Препринт научной статьи «Language Models Represent Space and Time» опубликован на сайте препринтов arXiv.org (arXiv:2310.02207).
Источник: habr.com